You can use validation functions as a tool to steer coding agents and data processing agents automatically, instead of manually copy pasting outputs or prompting. You can use this to parallelize common tasks in agentic programming, and eliminate bottlenecks on your agentic coding workflows.
The Standard Agent Loop
The industry consensus on a agentic loop looks something like this
msg = []
while True:
msg.append(input())
while True:
output, tool_calls = prompt_llm(msg)
msg.append(output)
print("Agent: ", output)
if tool_calls:
msg.extend([
handle_tool_call(tc)
for tc in tool_calls
])The Problem: Manual Verification
Agents operating on this premise trap you in a tedious cycle:
- Agent makes a change
- Manually run tests
- Paste the output back into the agent
- Repeat
While this workflow might feel productive you might start to feel bottlenecked by your ability to copy paste test outputs from window to agent time and time again. To automate this, get the agent to run the tests for you and feed the results of this test back into its context window. By automating this, you can free up your attention by running this in the background, and have confidence of reaching a stable state code wise.
Naive Solution: Bro, Just Prompt Harder
fix my failing test and verify your fix by running pytest
Steering the agent via a prompt is an okay way to implement this control flow. You are handing off the control flow to token output generation so that will make your control flow probabilistic in nature and subject to all of the fun consequences of that property. One example of a failure mode here is sometimes agents will just give up after so many tries of failing tests, instead of trying a different approach.
Control for Hallucination with Deterministic Validators
introducing validation directly into the agent loop feeds back validation context into the agent so that it does not complete its loop until the goals are met.
msg = []
while True:
msg.append(input())
while True:
output, tool_calls = prompt_llm(msg)
msg.append(output)
print("Agent: ", output)
if tool_calls:
msg.extend([
handle_tool_call(tc)
for tc in tool_calls
])
+ complete, output = check_completed()
+ msg.append(output)
+ if complete:
+ break
When an agent is ready to submit a completed task, the check_completed() function runs a verification command (like npm run test) or executes any validator that determines task completion. When the task remains incomplete, the validation output enters the message history, creating an automatic feedback loop.
flowchart LR
Agent -->|mutation with tools| Environment
Environment -->|observation with validators| Agent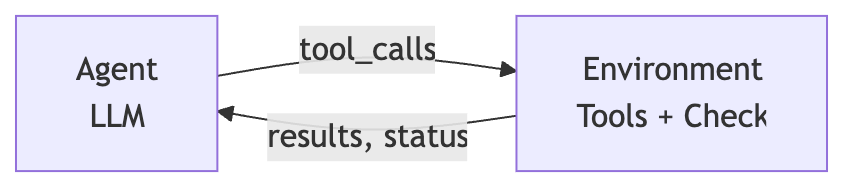
Why This Works
This approach gives the agent grounded, controlled access to environment state. Agents possess tools to inspect the environment, but prompt-based steering proves unreliable. Agents grow lazy, confused, or prematurely declare success.
Embedding environment state validation directly into control flow ensures the agent continues until either:
- The task is genuinely complete, or
- The token budget is exhausted
Critically, check_completed() validates the actual state resulting from the agent’s actions on the environment, not merely what the agent thinks it accomplished.
Implementation: Mini Agent Action
Mini Agent Action adapts Mini SWE Agent to implement this control flow. Install it with pip and run an agent with a bash tool that loops until task completion:
pip install mini-agent-action
mini-agent-action --exec "python test.py" \
--task "fix this test, you can see it fail with python test.py. you will be validated against that cmd" \
--debugThis sort of agent is very useful to have listening to your PR branches. When you push a commit with broken tests, instead of intervening, you can task switch and wait for this agent to come up with a solution to your test failure. Mini SWE Agent claims a 70% score on SWE bench without having this level of control on its outputs, and even if the agent doesn’t complete the task correctly, it will often be close enough to the correct answer that I am able to use part of its outputs in the final implementation. The agent creates a pull request on the feature branch, so I can choose to just merge, or close the pull request if I’m not happy with the results.
A system like this is proactively having agents fix your code, instead of having a programmer reactively prompting agents to intervene, while maintaining human ownership over the results.
Implementation: Data Transformation
Consider this common scenario: you receive JSON data that must conform to a specific schema. You could manually write transformation logic, but this approach fails at scale. Each new JSON structure requires custom transformation code—an unsustainable workload when handling diverse inputs.
Agents solve this by generating valid transformation code at runtime. Add a validation function to your agent loop that checks whether the transformed output matches your target schema. When validation fails, the agent reruns with debug information until it produces valid output.
flowchart TD
A[Input JSON] --> B[Generate Python code<br/>to transform data]
B --> C{Output matches<br/>target schema?}
C -->|No| B
C -->|Yes| E[Return valid JSON]
classDef default fill:#fff,stroke:#333,stroke-width:1px,color:#000
classDef decision fill:#f5f5f5,stroke:#333,stroke-width:1px,color:#000
class C decisionThis approach has limitations. Agents sometimes satisfy validation by emitting minimal, empty JSON documents. You may need multiple runs to get acceptable results. Still, this requires far less effort than writing custom transformations for each incoming schema.
Conclusion
Integrating automated validation into your agent’s control flow eliminates manual intervention and creates an autonomous system.